简介
正如 Wiki 中对最大似然估计的描述:
在概率统计中,最大似然估计是用来估计一个概率模型的参数的一种方法。
接下来,我们将从二项分布开始讲起。
假设,我们有个样本集:{0,1, 1, 0, 1, 1}其中样本集中不同数字对应的概率如下:
那么对应参数 的最大似然是什么呢?
我们可以将该样本集想象成投掷硬币的结果集,其中 1 表示正面,0 表示反面。从样本集看,投掷硬币的结果更偏向硬币的正面,但是有多大概率投掷的结果是正面呢?
让我们将每次投掷结果对应的概率相乘,并得到一个 的函数:
那么对 做对数变换:
在最大化的基础上,计算出 对应的值。 那么我们可以计算 对 的导数
从而 .
但是,我们并不确定 是最大值点,还是鞍点。所以我们通过计算 的二阶导来确定下:
我们将 带入上式得到的结果值是一个负数,所以 是函数 对应的最大值。
因此如果该样本集是投掷硬币的结果集,那么我们可以说投掷硬币有 的概率得到正面。
上述例子只包含一个参数()。
下面将介绍个更广泛的模型,用于估计多个参数的方法。
极大似然估计(MLE)
让我们看下下面的极大似然函数:
(1)
与上节中的似然函数 相比,公式(1)中的 就是对应的概率:
其中 是如下输入:
正如公式所示,使用逻辑回归去估计对应,样本的类别和相应的概率。
现在让我们来看下该模型对应的参数,如上定义的权重 对应的似然函数 。 当我们构建逻辑回归模型时,我们希望最大化似然函数。
换句话说,最大化似然函数就是最大化相应的概率值。但我们经常说的是损失,对极大似然函数取反作为损失函数
为了方便,我们可以将似然函数作为我们的损失函数。, 这样我们就可以使用梯度下降法进行相应的优化。
为了让我们更清晰的了解该损失函数,我们来看只有一个样本的损失函数:
如果我们仔细看下这个等式,当 时等式的第一项就消失了,当 时等式的第二项就消失了。正如下图所示:
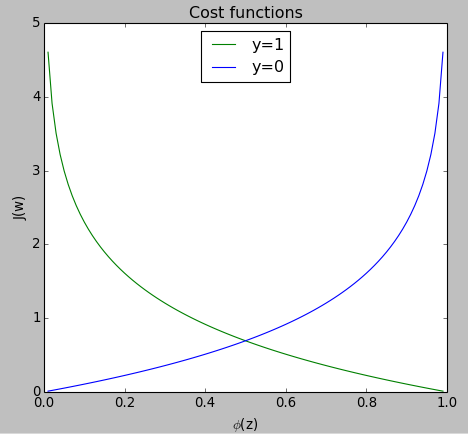
如图所示,我们可以看到当我们正确的预测一个样本的标签为 时损失函数的值接近于 0 (绿色曲线)。 从 轴看,但标签 时损失函数的值接近于 0(蓝色)。
图片对应的代码:
import matplotlib.pyplot as plt
import numpy as np
phi = np.arange(0.01, 1.0, 0.01)
j1 = -np.log(phi)
j0 = -np.log(1-phi)
plt.plot(phi, j1, color="green", label="y=1")
plt.plot(phi, j0, color="blue", label="y=0")
plt.xlabel('$\phi$(z)')
plt.ylabel('J(w)')
plt.title('Cost functions')
plt.grid(False)
plt.legend(loc='upper center')
plt.show()