简介
机器学习概述:
理解如何从数据中抽取特征来完成机器学习任务
- 特征提取涉及使用最少的资源来描述大量的数据
- 在对复杂数据进行分析时,最大的问题之一就是多变量的使用
- 大量变量的分析通常需要大量的内存和计算能力,也可能导致分类算法过度拟合训练样本,并且对新样本归纳得不好
- 特征提取是构建变量组合的方法的一个通用术语,用于解决这些问题,同时仍然以足够的精度描述数据。
- 理解监督学习的基本分类,包括回归学习算法或者分类学习算法
- 理解非监督学习的基本分类,包括降维分析算法或者聚类算法
- 理解线性可分数据和非线性可分数据的区别
特征和特征提取
下图展示了机器学习主要的处理流程:
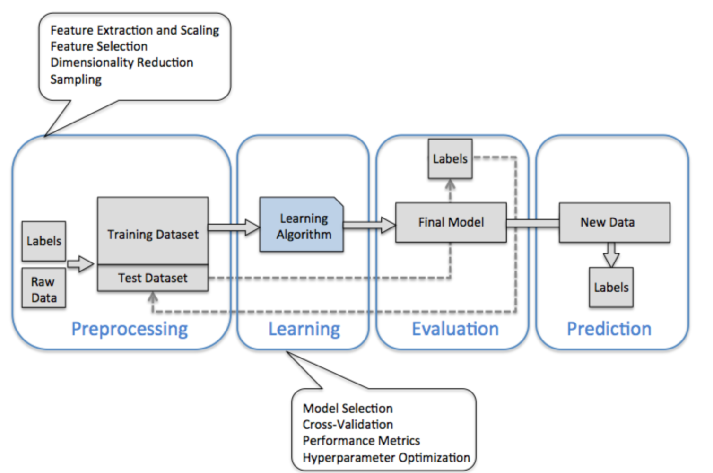
该图片来自于Python Machine Learning by Sebastian Raschka, 2015
预处理(Preprocess): 让数据成形,原始数据的格式往往很少能让机器学习算法直接使用,因为不同机器学习算法的输入形态是不同的。
所以预处理是机器学习应用过程中非常重要的一步处理。就像我们后面将会使用到的鸢尾花数据集,我们可以认为原始数据就是鸢尾花的图像,我们从这些原始图像中提取了相关有用的特征,比如花的颜色,色调,花的高度,宽度和长度等待。
有时候我们选择的特征中,有一些特征是高度相关的,所以在一定程度上存在着特征的冗余。在这种情况下,特征降维技术能将特征压缩到一个更小的子空间中。特征降维能有效的降低特征存储的空间,同时可以让学习算法计算的速度更快。
- 选择并训练一个有效的模型
评估模型并且将模型应用于一些新的数据上
在我们选定并在训练数据中训练得到一个模型之后,我们可以使用测试数据集来评估该模型在新数据上的表现,及获取测试错误率。
如果我们对该模型的表现比较满意,我们可以使用该模型来预测未来的新数据。
需要注意的是,上面提到的从训练数据中产生的特征降维模型也将一同被应用于测试数据,和未来的新数据中。
Scikit-learn and numpy
Scikit-learn高度优化并实现了机器学习的多种算法,并且对外提供了用户友好的API函数接口。
Scikit-learn包不经提供多种机器学习算法。同时提供许多便利的函数,例如:数据预处理,模型微调,或者是模型评估。
多数Scikit-learn中实现的机器学习算法都是采用 numpy 的array (n_samples, n_features) 作为输入。
- n_samples: 是样本个数
- n_features: 特征数
Iris flower data set
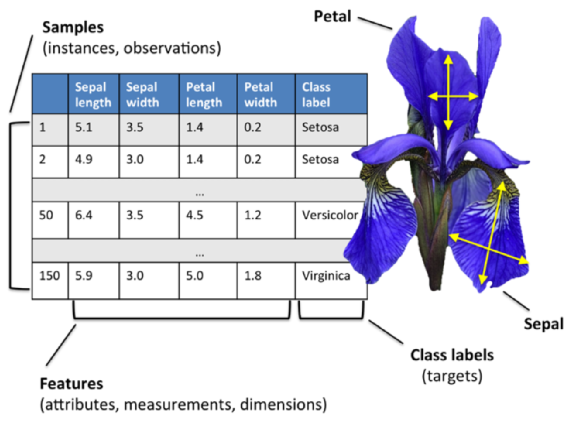
图片来自:Python Machine Learning by Sebastian Raschka, 2015
本文中的例子是五十个三种不同类型的鸢尾花样本数据,每个样本包含四个不同的特征,萼片和花瓣的长度和宽度,以厘米为单位。基于这四种特征,Fisher构建了一个线性判别模型来区分这些不同类型的花。更多关于鸢尾花样本数据的描述,请看iris flower data set。
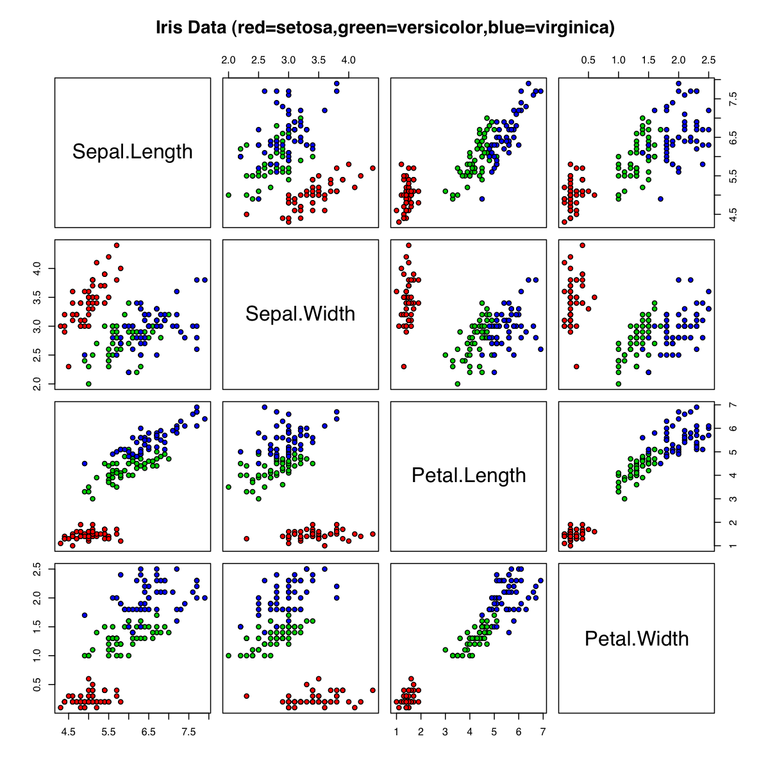
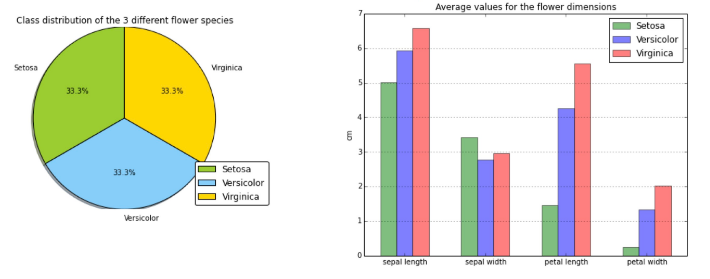
Iris data set 和 scikit-learn
scikit-learn 将csv格式的数据加载进程序中构建numpy array:
>>> from sklearn.datasets import load_iris
>>> iris = load_iris()
其中 dataset 的 data属性存放了所有样本的特征数据。
>>> iris.data
array([[ 5.1, 3.5, 1.4, 0.2],
[ 4.9, 3. , 1.4, 0.2],
[ 4.7, 3.2, 1.3, 0.2],
...
[ 6.5, 3. , 5.2, 2. ],
[ 6.2, 3.4, 5.4, 2.3],
[ 5.9, 3. , 5.1, 1.8]])
>>>
>>> n_samples, n_features = iris.data.shape
>>> n_samples
150
>>> n_features
4
>>> iris.data.shape
(150, 4)
dataset 的 target 属性存放了不同样本对应花的类别
>>> len(iris.target)
150
>>> iris.target
array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2])
其中 target_name 存放了样本类别的名称
>>> iris.target_names
array(['setosa', 'versicolor', 'virginica'],
dtype='|S10')
如果我们只想提取该数据集特征集的部分数据,例如:我们只想得到花瓣的宽度和长度,我们可以通过以下方式来获取。
>>> from sklearn import datasets
>>> import numpy as np
>>> iris = datasets.load_iris()
>>> X = iris.data[:, [2, 3]]
>>> X
array([[ 1.4, 0.2],
[ 1.4, 0.2],
[ 1.3, 0.2],
[ 1.5, 0.2],
...
[ 5. , 1.9],
[ 5.2, 2. ],
[ 5.4, 2.3],
[ 5.1, 1.8]])
如果我们使用np.unique(y)来返回iris.target中不同类别数字标记,我们可以看到不同鸢尾花类别用不同数字表示了。
>>> y = iris.target
>>> np.unique(y)
array([0, 1, 2])