本文主要主要介绍被应用于图像识别和分类问题的卷积神经网络(CNN)的体系结构及内部处理逻辑。
阅读本文前,需要大家对神经网络有一定的了解。如果不了解,请阅读该文章
目录
1. 图像在计算机中的存储形式
人类的大脑是非常强大的处理器,我们每分每秒都在通过眼睛接收不同的图像,并且能在毫无察觉的时间内处理图像。但是,其他机器并非都能做到。在进行图像处理的首要前提是,要知道在计算机中图像是如何表示并存储,从而能够让计算机能够正常的读取图像。
简单来说,每幅图像都是通过像素点在空间中特定的组合排序组成,只要你修改图像中像素点的位置或者颜色值,那么你对应的图像也就会变的与原来不一样。让我们举个简单的例子,你想存储并读取一张带有数字4的图像。
那么计算机可能会把图像分解成一个矩阵,并且存储图像中不同位置上像素点的颜色。其中值1 表示白色,值256表示黑色。
一旦你使用这个方式存储了图像,那接下来问题是如何让神经网络理解这种编排方式及内部的模式特征。
2. 如何帮助神经网络算法去识别图像
每个图像中的数字都是像素点根据特定的排序组合而成的。
如果我们想使用全连接神经网络来识别数字图像,那么我们该怎么做呢?
在使用全连接网络中,首先会将图像矩阵拉平成一个的数组,并将数组中的像素作为特征,从而来识别图像中的数字。对于神经网络来说,确实很难知道底层到底怎么处理的。

对于人而言,也很难理解拉平后的数组是数字4,因为我们失去了像素点的空间信息。
除了上述的拉平矩阵外我们还能怎么做呢?让我们看下怎么通过从原始图像提取特征从而保留像素的空间特征。
Case 1:
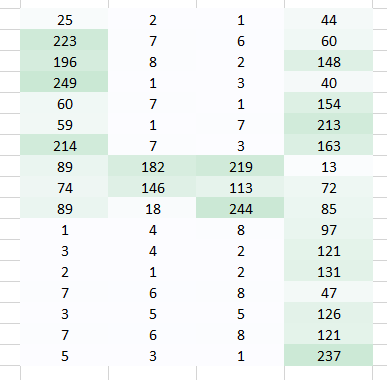
在这我们使用一个权重值乘以图像中的每一个像素点。
从图中,我们使用肉眼还是能正常的识别出这是一个数字4。但是把它放进全连接网络中,又会将图像拉平成一维数组。所以我们还是无法保留像素直接的空间信息。

Case 2:
从上面的例子中,我们知道将矩阵拉平破坏了图像的空间信息。我们需要寻找一个将图像放入网络中,但是不破坏图像的空间信息的方法。
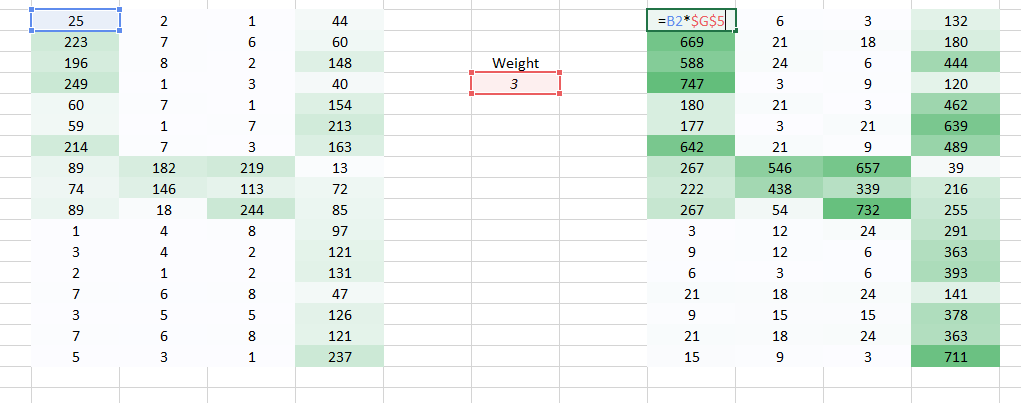
让我们来看下,相比直接使用一个像素点,我们可以尝试整合相邻两个像素点之间的信息。这可以让网络了解相邻像素之间的关系。现在我们一次考虑两个像素点,那么我们就需要一次使用两个权重。
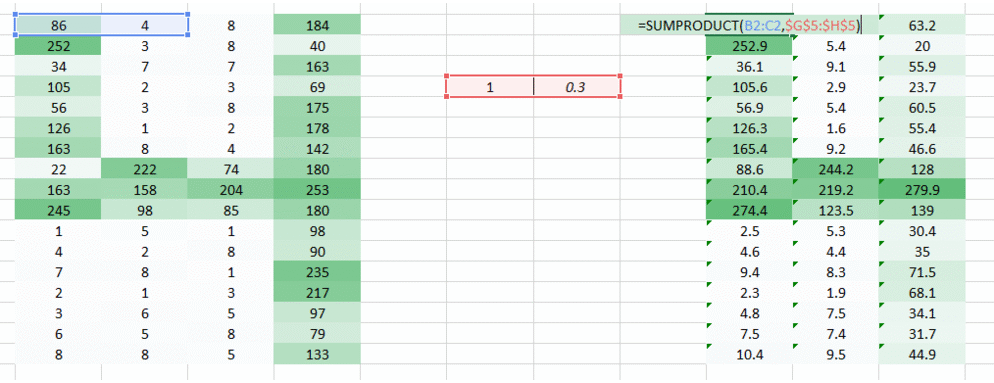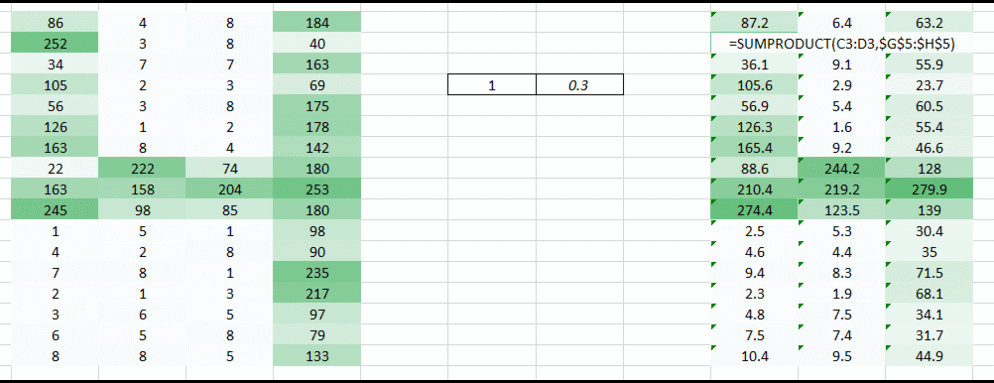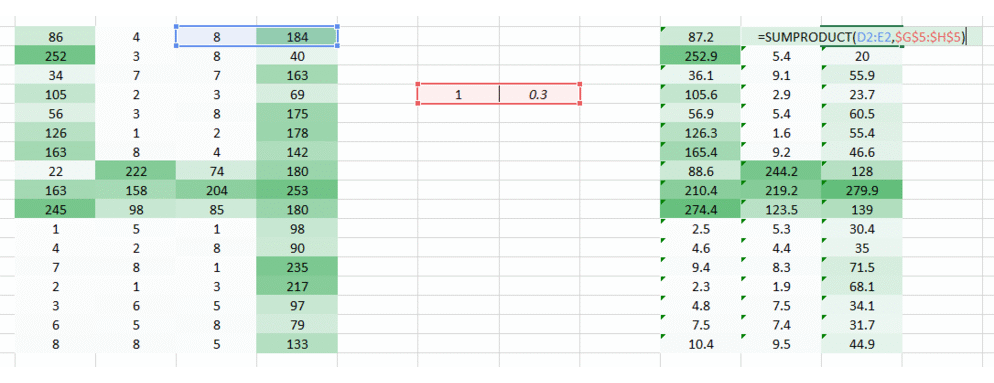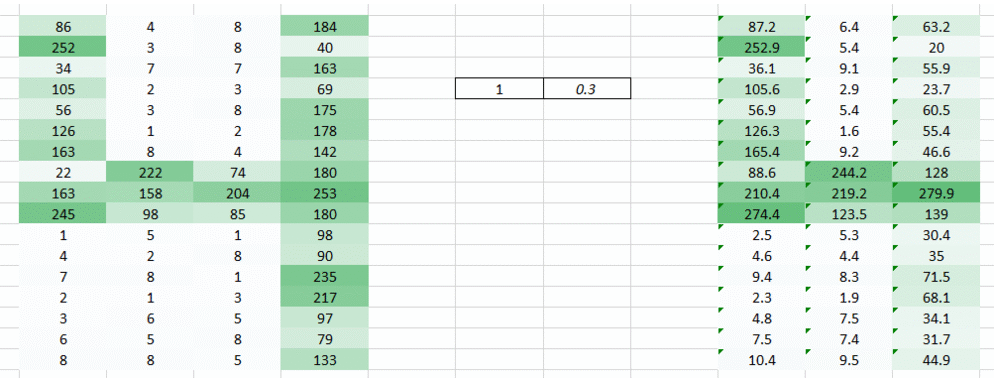
从图中我们可以看出,原来包含4列的矩阵,通过变换后变成了3列矩阵。我们一次使用两个像素点,从而图像在处理后就变小了。虽然图像变小了,但是我们还能清晰的看出来图像中的数字是4。同时,有一个比较重要的点,我们需要认识到,就是我们只考虑了水平方向两个相邻像素点的信息,因此也就只有水平方向的空间特征得以被考虑。
这是其中一种从图形中提取特征的方法。 我们能够清晰的看到图形的左边和中间的形状,但是图形右边形状略微有点不够清晰。这主要是因为下面的两个主要问题:
- 图形右边的像素点与权重只相乘了一次
- 因为左边的权重值(1)大于右边的权重值(0.3) 所以左边的信息被放大了,右边的信息被缩小了。
那么现在我们遇到了这两个问题,我们就需要两种方法来解决。
Case 3:
对于图像左边缘和右边缘的像素只被处理一次的问题。从而我们需要做的是让神经网络也对这部分像素点处理与其他像素点采用相同的处理手法。
我们有个简单直接的方法,沿着权重运动的方向两侧放置零点。
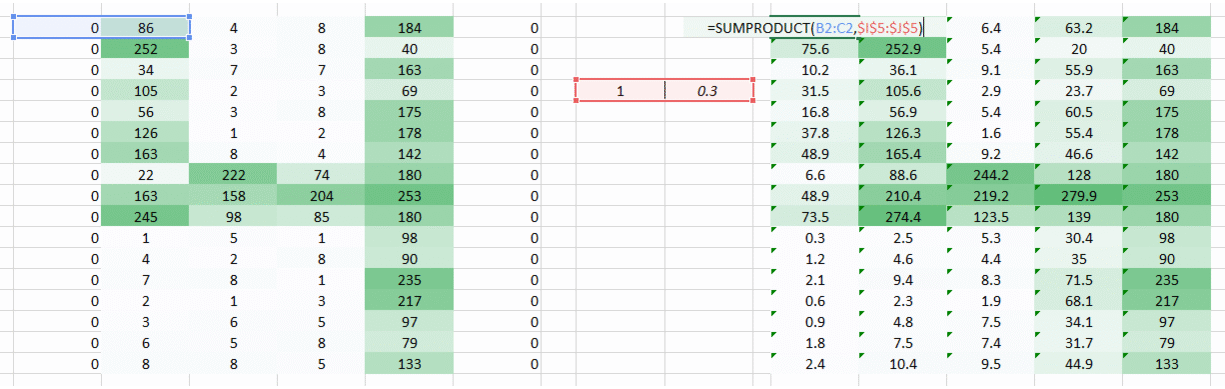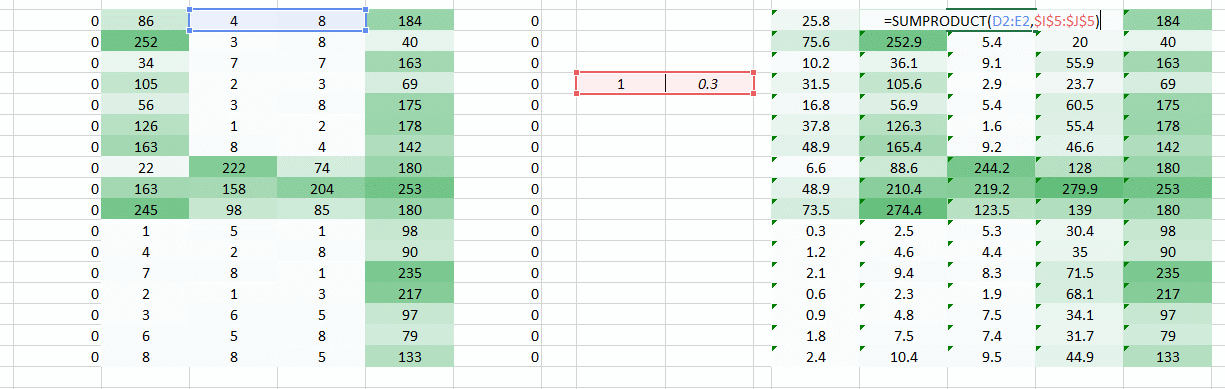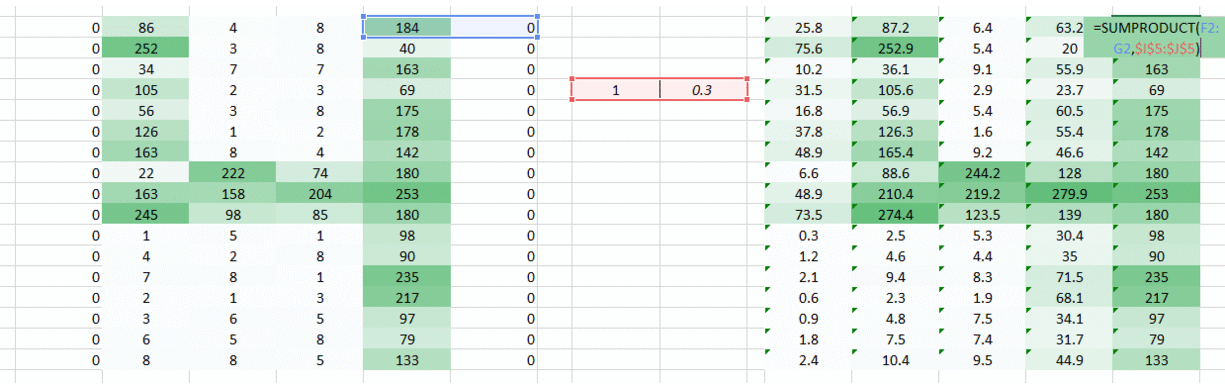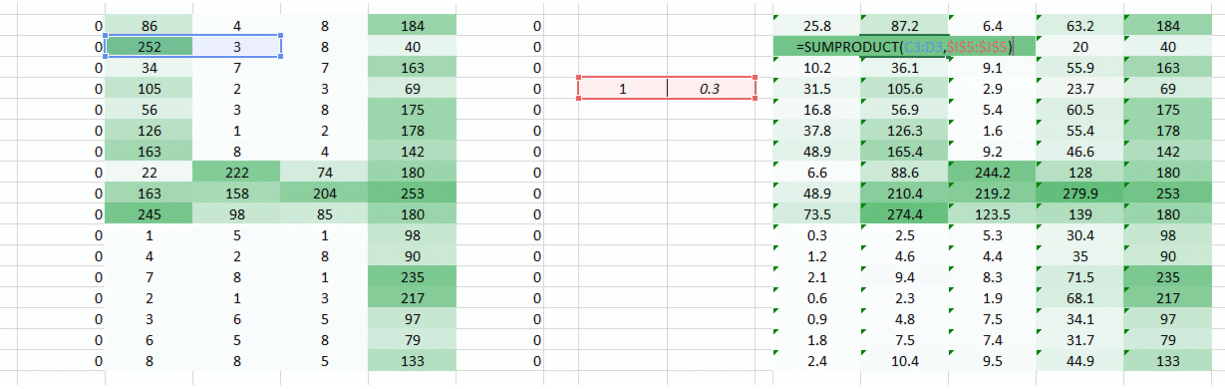
你可以看到,通过添加零来保留角落的信息。图像的大小也随之增加了。当我们不想让图像的大小变小时可以使用这个方法。
Case 4:
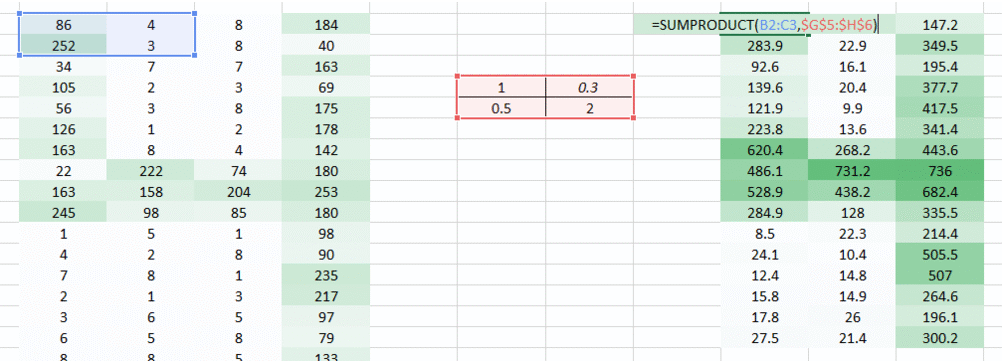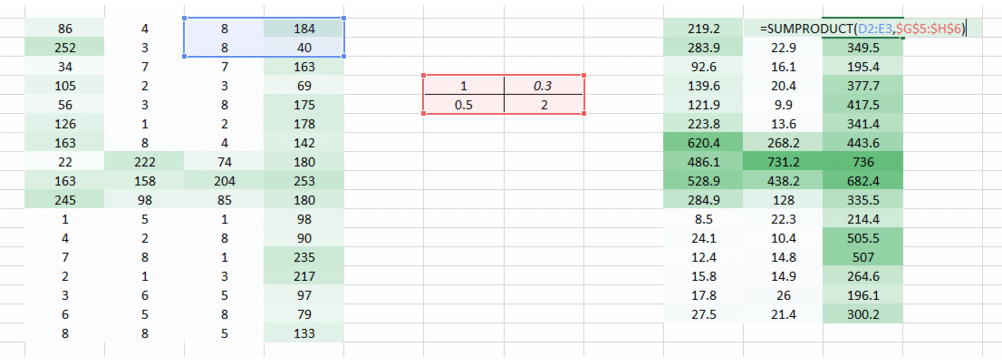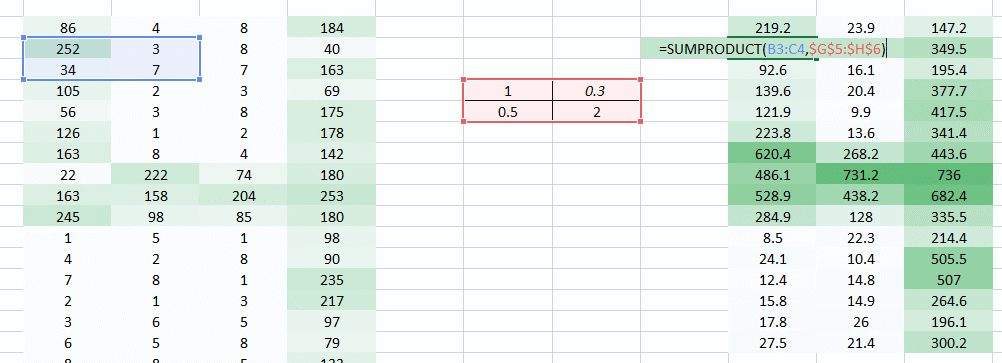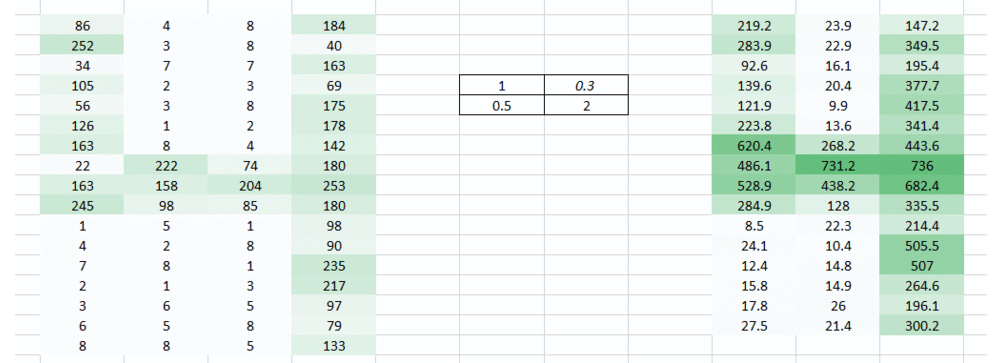
在这我们想解决的一个问题是,因为右边的权重值较小使得右边的像素值降低,从而导致我们难以识别。我们能做的就是将多个权重值的结果结合在一起。
权重 我们得到了下面的结果:
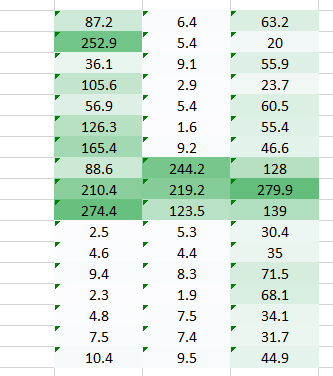
当使用权重 我们得到了下面的结果:
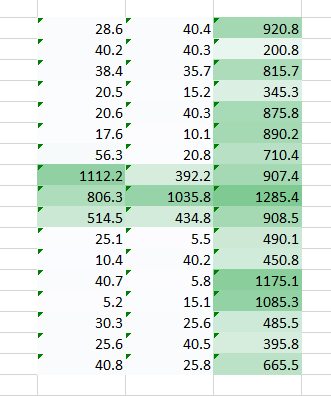
结合上述两个输出结果,我们能更清晰的看到图像中数字。因此,我们所做的只是使用多个权重而不是一个来保留关于图像的更多信息。最终的输出将是上述两张图像的结合。
Case 5:
上述的提取特征的方法都只是保留了图像水平方向的空间信息。但是在很多时候,我们希望保留除了水平方向之外垂直方向的空间信息。我们可以将原来一维权重数组转换成二维权重矩阵,这样来考虑图像中水平和垂直方向的信息。同样,相比原图像,经过权重变化后的图像在行和列都少了一。
最终我们到底做了什么
我们上面做的是试图通过使用图像的空间排列从图像中提取特征。对于神经网络而言,了解图像中像素的排列方式,对于我们了解图像中的信息是非常重要的。我们上面做的也正是卷积神经网络(CNN)所做的。我们可以采用输入图像,定义权重矩阵,并将输入卷积以从图像中提取特定特征,而不会丢失关于其空间布置的信息。
3. 定义一个卷积神经网络(CNN)
在定义一个卷积神经网络前,我们需要知道三个基本的定义:
- 卷积层
- 池化层(可选)
- 结果输出层
3.1 卷积层(Convolution layer)
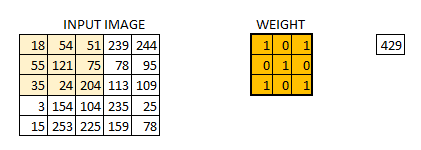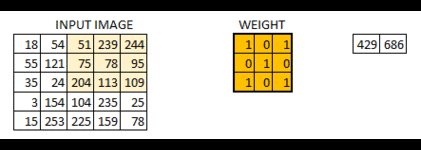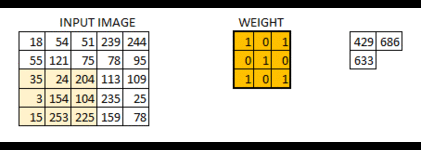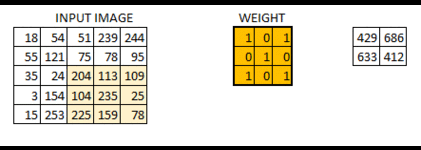
在卷积层中具体的处理手法,与上面Case5所描述的是一样的。 假设我们有个 大小的图像。同时我们定义一个权重矩阵,从而来提取图像中特征。
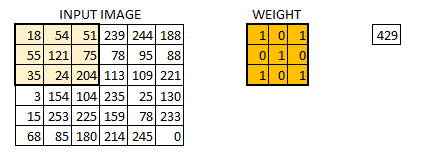
我们初始化权重为 3*3 的矩阵。将该权重矩阵扫过图像中的每个像素并得到不同像素点的卷积输出。上图中的结果 429 就是通过点乘权重矩阵和图像对应的像素并求和得到的结果。
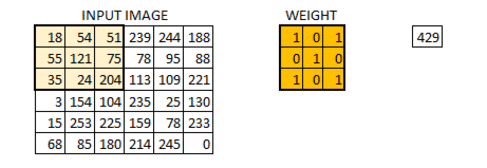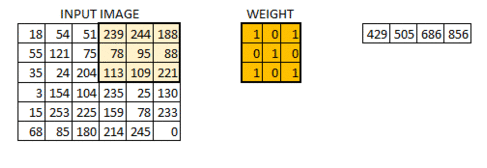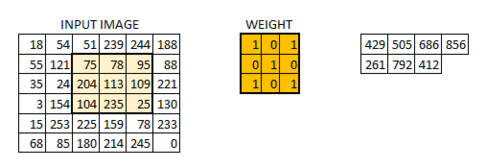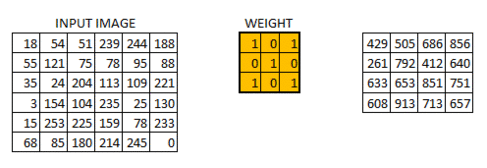
这幅的图像最终被卷积成了的图像。如果我们把权重矩阵想象成粉刷,那么对图像的卷积就可以想象成在刷一面墙。权重刷子先水平从右向做刷墙,然后垂直从上到下刷墙。
让我们在真实的图像上看下通过卷积后的图像效果:

其中权重矩阵就像是不同的滤镜,这些滤镜从图像中提取不同的特征信息。其中一些可能提取是边缘特征,其他的一些可能提取的是颜色特征,又或者一些只是过滤掉一些不想要的噪声。
这些权重都是通过最小化损失中学习出来的,与MLP(多层感知机)的学习过程类似。从图像中学习出来的权重帮助神经网络更好的做出正确的预测。当我们包含多层卷积层时,初始的几层提取一些更普适的特征,随着网络层次的深入,通过卷积获得的特征会越来越复杂,也会越来越适应我们处理的问题。
步幅(stride)和填充(padding)的概念
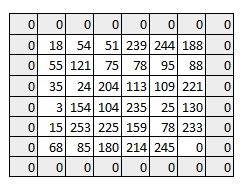
如上所述,权重矩阵对整幅图像一个一个像素的扫描计算。我们可以将权重矩阵如何在图像上移动作为一个超级参数。如果权重矩阵每次移动一个像素,那么我们就称步幅(stride)为1,让我们看下如果步幅为2的情况下是怎么样的?
正如你所看到的,图像的大小随着步幅的增大在不断的减少。那么通过往图像中填充(padding) 0值,我们就可以解决这个问题。我们同样可以多填充一些0值,从而避免步幅增大导致图像减小的问题。
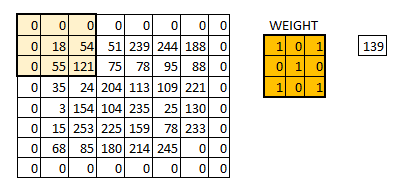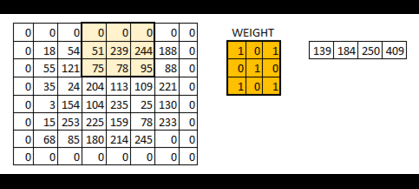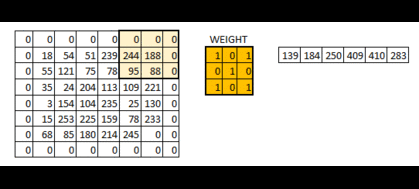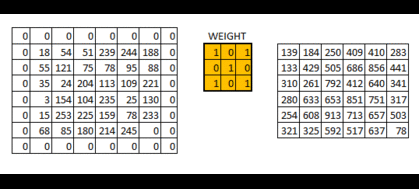
在用零填充后,我们可以看到图像初始形状是如何保留的。这就是所谓的相同的填充(same padding),因为输出图像与输入大小相同。
通过填充后,我们保留了更多的边界信息,并保留了图像的原始大小。
多层卷积核和激活图像
我们需要知道的一点,权重的深度方向的维度与输入图像深度方向的维度应该保持一致。因此通过一维卷积核我们能获得一维深度的卷积图像。在多数情况下,同时使用的是多个相同尺寸的卷积核,而不仅仅是使用单一卷积核。
通过不同卷积核处理后的图像重新组合在一起形成多维卷积图像。假设我们有个 的输入图像,我们使用10个的卷积核对输入图像做卷积,那么我们就会得到一个 的输出结果。

3.2 池化层(pooling layer)
有时候输入图像的尺寸太大,我们需要减少需要训练的参数个数。所以比较直接的做法就是在不同的卷积层中引入池化层。池化层主要目的是为了减少图像的空间大小。池化是独立作用在输入图像的不同深度上,因此图像的深度信息经过池化处理后还是保持不变。最常用的池化操作有最大池化(max pooling)。
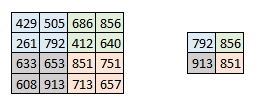
上图所示,我们使用的步长等于2,同时池化维度也是2。最大化处理会对不同深度的图像进行处理,正如我们所看到的一样, 的卷积输出在最大化池化后变成了 的输出图像。
让我们看下在真实图像上做最大池化后得到的图像

如图所示,我们在卷积图像上做最大化池化处理,可以看出最大化池化任然保留了图像的信息(一辆车停在路边)。如果你仔细看池化后图像的大小是原来的一半。这样可以帮助我们减少训练参数。
同理,还有其他的池化方法,比如均值或者 范式。
输出维度计算
在通过不同卷积层后,往往我们会对输入输出图像的维度是多少感到困惑。在这将做些简单介绍,从而让大家能很好的计算不同输出层图像的维度。
- 卷积核的个数,输出卷积图像的深度与给定的卷积个数相等。正如我们上面介绍多层卷积核和激活图像时所描述的,激活图像的深度与输入的卷积个数是相同的。
- 步幅(stride),如果我们采用一步移动,那么输出图像的维度分别减一。若使用更大的步幅,将会得到更小维度的输出图像
- 零填充(Zero padding), 这可以帮助我们保留输出图像与输入图像的维度的一致。如果采用一步步幅,并在图像边缘填充一行或列的零值,那么输出的卷积图像维度与输入的原图是一致的。
通过上面的描述,我们可以采用一个简单的公式来计算输出图像的维度信息。我们可以使用 。 其中 是输入图像的维度, 是卷积核的维度, 是填充的维度, 是对应的步长信息。假设我们有个输入图像,其维度为: 我们使用一个 的卷积核,一步步长,不填充。
所以 输出图像的深度与卷积核个数相同例如:10。 输出图像的维度信息的结果 。 所以输出的volume的维度为
3.3 输出层
在通过不同卷积层(convolution layer),池化层(pooling layer)处理后,我们任需要输出相应的类别信息。其中卷积层,池化层只能帮助我们从原始图像中提取相应特征和降低参数的个数。但是为了能得到最后的输出结果,我们需要使用一个全连接层,从而得到最终的我们需要的数字输出。如果仅仅使用卷积层,我们很难获取到我们想要得到的结果。卷积层输出3D的激活图像,但是我们只想知道图像中的数字是多少,或者该图像是否属于特定的类别。在输出层中同样也会包含一个损失函数,例如:categorical cross-entropy,来计算预测结果的偏差。一旦前向传播处理结束后,后向传播就会根据损失函数重新更新网络中每一层的权重,从而使得损失降低。
3.4 构建整个CNN网络
CNN 是由不同的卷积层和池化层有机的组合而成的。让我们看下整个网络将会是怎么工作的。
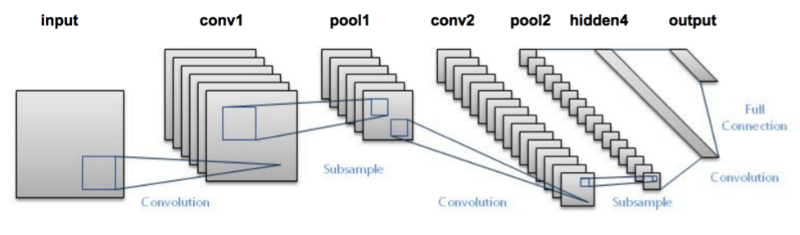
- 向第一层卷积层输入原始图像。卷积输出是一个激活图像。不同的卷积核作用在图像上从而获取不同的特征,并且不断的深入。
- 不同的卷积核应该提取不同特征,从而帮助我们准确的预测到相应的结果。
- 池化层进一步降低参数的个数
- 在最后做出预测前,多层卷积层和池化层帮助我们提取图像的不同特征,同时降低训练参数的个数。
- 正如上面描述CNN的输出层是一个全连接神经网络。首先将其他不同层输出的图像拉平,并作为全连接网络的输入,最后用于预测相应的特征
- 最后通过计算输出层的输出结果与真实结果的误差,比如均方误差。然后计算误差的梯度。
- 结果的误差通过后向传播来更新不同卷积的权重和偏差(bias)
- 一次前向传播和后向传播构成了一个完整的训练过程。