通过顺序特征选择做特征降维
顺序特征选择是特征降维方法中的其中一种方法,特征降维通过降低模型的复杂度可以用来避免模型的过拟合。
顺序特征选择通过不断的选择蕴含信息最多的特征集进行学习,然后在已有的特征集基础上进一步选择合适的特征再次学习。
降维的另一种方法就是特征提取,从已有的特征集中选择出合适的特征子集作为最终的特征集。
顺序特征选择相关算法
顺序特征选择算法(sequential backward selection SBS)将初始化的d-维特征降低至k-维特征。它是贪婪搜索算法中的一种。
它能自动的选择出一个与问题最相关的特征子集,通过减少不相关的特征和特征噪声来降低模型的泛化错误和提高模型的执行效率,这对于无法使用正则化的算法是非常有帮助的。
后向顺序特征选择算法,选择所有属性放入集合,第一次拿出一个识别率最低的属性,然后依次拿出属性直到拿出一个属性后该属性集合的性能不升高反而下降。
具体的实现步骤:
- 初始化算法:, 其中 是整个特征空间的特征维度
- 通过判断 来决定是否保留特征
- 从特征集中删除无用特征
- 若特征维度达到 , 则停止,否则继续第二步操作
将SBS应用于KNN分类器
接下来我们看下如何使用SBS算法,我们以 KNN 分类算法为例:
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier(n_neighbors=2)
sbs = SBS(knn, k_features=1)
sbs.fit(X_train_std, y_train)
<main.SBS instance at 0x7fc41c93a488>
k_feat = [len(k) for k in sbs.subsets_]
plot(k_feat, sbs.scores_, marker='o')
ylim([0.7, 1.1])
ylabel('Accuracy')
xlabel('Number of features')
grid()
show()
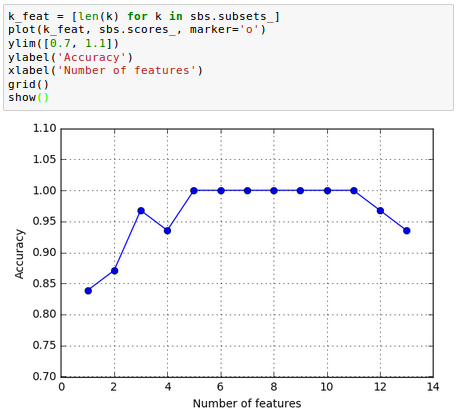
从图中可观察得到,通过降低特征的维度,KNN的识别准确率在不断上升。同时在 时识别准确率达到了100%
让我们看下是哪五个特征能使得在测试集上有如此好的表现
k5 = list(sbs.subsets_[8])
print(df_wine.columns[1:][k5])
Index([u’Alcohol’, u’Malic acid’, u’Alcalinity of ash’, u’Hue’, u’Proline’], dtype=’object’)
从上代码中可知, 在 sbs.subsets_ 中对应的是第九个元素。同时我们从 pandas 的 dataframe 中获取对应的列名。
sbs.subsets_
[(0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12),
(0, 1, 2, 3, 5, 6, 7, 8, 9, 10, 11, 12),
(0, 1, 2, 3, 6, 7, 8, 9, 10, 11, 12),
(0, 1, 2, 3, 6, 7, 8, 9, 10, 12),
(0, 1, 2, 3, 6, 7, 8, 10, 12),
(0, 1, 2, 3, 6, 8, 10, 12),
(0, 1, 3, 6, 8, 10, 12),
(0, 1, 3, 6, 10, 12),
(0, 1, 3, 10, 12),
(0, 1, 10, 12),
(0, 1, 10),
(0, 10),
(0,)]
sbs.subsets_[8]
(0, 1, 3, 10, 12)
接下来,我们来看下该KNN分类器在原始测试集上的表现
knn.fit(X_train_std, y_train)
print('Training accuracy:', knn.score(X_train_std, y_train))
print('Test accuracy:', knn.score(X_test_std, y_test))
(‘Training accuracy:’, 0.9838709677419355)
(‘Test accuracy:’, 0.94444444444444442)
上面的代码中,我们使用原始的全量的特征数据训练KNN分类器,并将最终训练得到的模型应用于测试集,从识别准确率来看,测试准确率要比训练准确率要低。从某种程度上感觉有点过拟合了(overfitting)
接下来,我们用选择出来的五个特征来训练KNN
knn.fit(X_train_std[:, k5], y_train)
print('Training accuracy:', knn.score(X_train_std[:, k5], y_train))
print('Test accuracy:', knn.score(X_test_std[:, k5], y_test))
(‘Training accuracy:’, 0.95967741935483875)
(‘Test accuracy:’, 0.96296296296296291)
通过训练原来一半的数据,但是我们获得了2个点的提高。同时减少了过拟合的可能性。
通过随机森林评估特征的重要性
在前面的章节中,我们使用 L1正则化 去除一些无关的特征,使用SBS算法做特征选择,随机森林是另一种从数据集中选择相关特征的方法。
不同于 L1正则化, 随机森林在scikit-learn实现过程中已经帮助我们算好了每个特征的重要性。所以我们只需要使用 feature_importances_ 来获取相关特征的重要性就可以。
通过特征重要性度量对其进行排序
让我们训练一个包含10000棵树的随机森林
我们将根据特征重要性,来对训练集wine中的13个特征进行排序
from sklearn.ensemble import RandomForestClassifier
df_wine.columns[1:]
Index([u'Alcohol', u'Malic acid', u'Ash', u'Alcalinity of ash', u'Magnesium',
u'Total phenols', u'Flavanoids', u'Nonflavanoid phenols',
u'Proanthocyanins', u'Color intensity', u'Hue',
u'OD280/OD315 of diluted wines', u'Proline'],
dtype='object')
feat_labels = df_wine.columns[1:]
forest = RandomForestClassifier(n_estimators=10000, random_state=0, n_jobs=-1)
forest.fit(X_train, y_train)
importances = forest.feature_importances_
indices = np.argsort(importances)[::-1]
for f in range(X_train.shape[1]):
print("%2d) %-*s %f" % (f + 1, 30, feat_labels[f],importances[indices[f]]))
- 1) Alcohol 0.182483
- 2) Malic acid 0.158610
- 3) Ash 0.150948
- 4) Alcalinity of ash 0.131987
- 5) Magnesium 0.106589
- 6) Total phenols 0.078243
- 7) Flavanoids 0.060718
- 8) Nonflavanoid phenols 0.032033
- 9) Proanthocyanins 0.025400
- 10) Color intensity 0.022351
- 11) Hue 0.022078
- 12) OD280/OD315 of diluted wines 0.014645
- 13) Proline 0.013916
title('Feature Importances')
bar(range(X_train.shape[1]), importances[indices],
color='green', align='center')
xticks(range(X_train.shape[1]),
feat_labels, rotation=90)
xlim([-1, X_train.shape[1]])
tight_layout()
show()
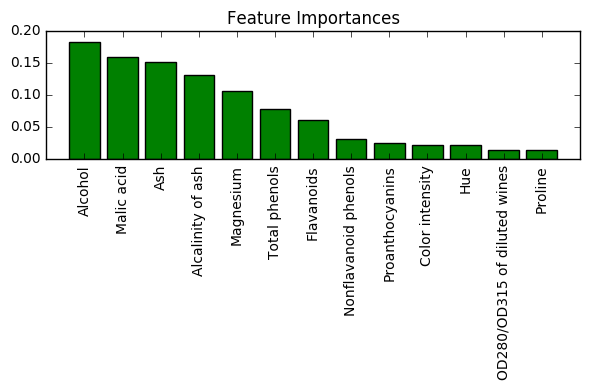
如上图所示,wine 数据集中的特征根据特征的重要性进行了排序,其中特征重要性都进行了归一化,所以他们值的和等于1.0
从上图中可以看出,葡萄酒的酒精度是最具有区分性的特征。
随机森林特征重要性需要注意的一个地方:如果某些特征是高度相关的,则一个特征可能重 要性会被排的非常高,但其他特征的重要性可能会相应的降低。但是如果我们只关心模型的 预测能力,而不是解释特征的重要性,我们可以不关心这类问题。